The Polymer stack
When building out the interoperability hub for Ethereum, these design principles were guiding us:
- we believe IBC is the best positioned candidate to provide a universal transport protocol for all chains, so Polymer aims to facilitate and accelerate IBC adoption
- we are committed to open-source contributions and aim to build our technology as much as possible by using and extending open-source technology stacks
- we value the highest level of engineering standards, and build to scale for the explosive future of the industry
With those principles in mind and after considerable research on different technology stack, we landed on the following architecture:
- Polymer will be built as a Cosmos SDK (ABCI) application, leveraging ibc-go, the most mature implementation of IBC in production
- Polymer will be built as an Ethereum rollup, leveraging the OP Stack developed by the Optimism Collective

In essence, the Polymer architecture leverages the flexibility in terms of execution engine in the OP Stack to build Ethereum rollups. The most interesting execution engine for Polymer, is the Cosmos SDK with its top-notch developer UX and tooling and a native IBC implementation.
The technical challenge thus, is to enable migrating the Cosmos SDK framework for creating sovereign L1s and turn it into a rollup framework in combination with the OP Stack. Or said differently: we build the framework to build Cosmos SDK rollups on Ethereum.
Consider the following diagram to study the architecture of Polymer, the interoperability hub connecting Ethereum rollups.
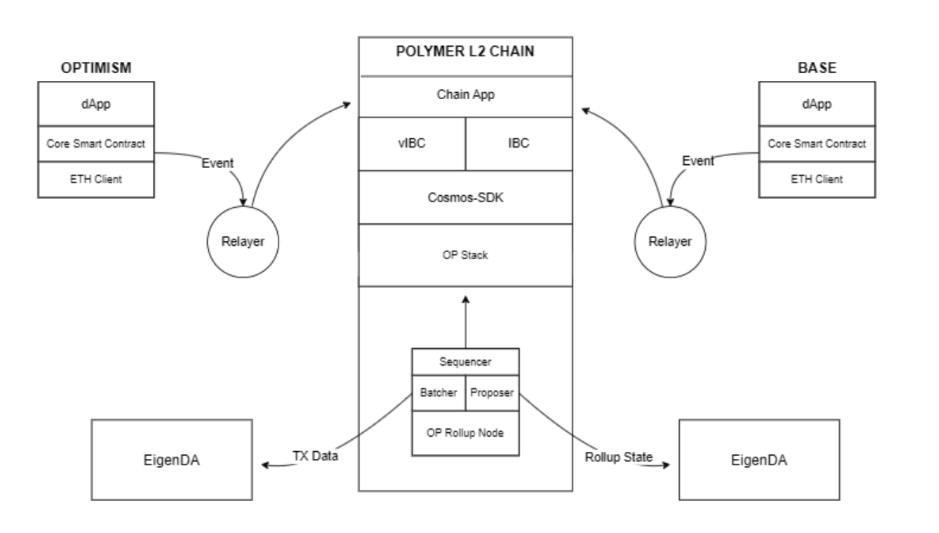
OP stack as rollup framework
To summarize what the OP stack is, we refer to the official documentation:
The OP Stack is a common development stack for building L2 blockchain ecosystems, built by the Optimism Collective to power Optimism. The OP Stack is best thought of as a collection of software components maintained by the Optimism Collective that either help to define new layers of the stack or fit in as modules within the stack.
More specifically, the current state of the OP stack (implemented and proposed/imagined) is depicted below.
We'll give a quick overview of the most important components as they are used (and potentially modified) to suit Polymer's needs.
When moving from the original OP Mainnet (formerly just Optimism) design to the modularized OP stack architecture, the different roles played by the sequencer node got a more modular design where it's feasible to swap out certain components with other ones.
As a result, there was an update with respect to the semantics when considering the different functionality of a sequencer node (block derivation & production, transaction batching and submitting to a DA layer, proposing new blocks to L1). Be sure to understand the processes underpinning the rollup architecture, while realizing there may be variation in the terms being thrown around.
Rollup node
A rollup does not have a consensus mechanism like the Ethereum L1 driving block production. Instead, the so called rollup node component derives L2 blocks from L1 data according to a derivation protocol.
The rollup node can be used in different modes, not only for sequencing. From the OP stack docs:
- Verifying the canonical L2
- Participating in the L2 network
- Sequencing transactions
When ran in sequencing mode, the rollup node will create new L2 blocks.
As shared sequencer solutions are still being investigated, Polymer initially will be running a single sequencer node and consider updating to a shared sequencing model when it is sufficiently mature.
Batcher & proposer
A rollup node ran in sequencing mode will have to collect batches of transactions and submit it to a data availability layer as well as post the state roots after execution and post it to the settlement layer.
These functions are performed by separate processes that are sub-components of the rollup node, called the batcher and the proposer.
Data availability (DA)
The OP stack has worked towards providing an interface for data availability that allows many DA layers to be used, not only the Ethereum L1 but also Celestia or EigenDA.
For the Polymer chain, initial testing will use Ethereum L1 but we will move to using EigenDA for testnet and mainnet.
Execution
Arguably the most enticing feature of the OP stack as a modular stack to build rollups, is the ability to use the rollup node architecture but swap in a different execution environment than OP Mainnet's slightly altered but EVM equivalent EVM, op-geth.
The execution layer receives the derived L2 blocks from the rollup node via the Engine API, and computes the state transitions resulting from it.
In the block derivation loop or state transition function loop (STF loop), all kinds of raw input data obtained from the DA layer can be used to derive the payloads to the Engine API (which then passes it on the the execution layer). These payloads can be in the format of any execution environment, provided the format is known by the derivation layer (i.e. the rollup node).
For Polymer, the execution engine will be a Cosmos SDK ABCI application which we discuss in more detail below.
Cosmos SDK as execution engine
Polymer's main focus when picking an execution engine is to have the most mature and feature-rich implementation at our disposal to build out the Polymer interoperability hub. That implies using the ibc-go implementation that is part of the Cosmos SDK.
From the Cosmos SDK documentation:
The Cosmos SDK is an open-source framework for building multi-asset public Proof-of-Stake (PoS) blockchains, like the Cosmos Hub, as well as permissioned Proof-of-Authority (PoA) blockchains. Blockchains built with the Cosmos SDK are generally referred to as application-specific blockchains.
So how does a framework to build standalone chains enable us to use it as execution engine in the OP Stack's architecture? This is possible due to the Cosmos SDK architecture and the Application Blockchain Interface or ABCI.
The default consensus engine in Cosmos SDK chains is the CometBFT engine, based on Tendermint consensus. The Cosmos SDK was initially designed to build the applications that use the CometBFT engine for consensus and networking. However, they are separate layers interacting through a minimal interface, ABCI. Read the Cosmos SDK docs on ABCI for more information.
+---------------------+ +---------------------+ | | | | | Application | | Application | | | | | +--------+---+--------+ +--------+---+--------+ ^ | ^ | | | ABCI | | ABCI | v | v +--------+---+--------+ +--------+---+--------+ | | | | | | | | | CometBFT | | OP-Node | | | | | | | | | +---------------------+ +---------------------+
The benefit of this approach is that an application built using the Cosmos SDK framework, can swap out to a different consensus engine, or in this case, to be used as execution engine in the OP stack!
Combined, we can say that the Polymer application (i.e. interoperability hub) is built as a Cosmos SDK ABCI app that is used inside the OP Stack to build a Cosmos SDK rollup. In this case, as we'll use Ethereum L1 as settlement layer, it is a rollup on Ethereum.
Virtual IBC as the application-specific component
Polymer as a Cosmos SDK rollup on Ethereum, is an example of an application specific rollup. It includes virtual IBC as its application-specific module, the secret sauce for Polymer to acts as interoperability hub taking on the interoperability workload for Ethereum rollups. Read more about it in a next section.
While the architectures of both OP stack and Cosmos SDK theoretically allow for components to be swapped in a modular fashion, the implementation details are still under active development and are non-trivial.
Polymer is taking on this work and intends to contribute back to the frameworks in due time. If you're interested in collaborating in the meantime, reach out to us!